31. Capsule Networks
Alternatives to Pooling
It's important to note that pooling operations do throw away some image information. That is, they discard pixel information in order to get a smaller, feature-level representation of an image. This works quite well in tasks like image classification, but it can cause some issues.
Consider the case of facial recognition. When you think of how you identify a face, you might think about noticing features; two eyes, a nose, and a mouth, for example. And those pieces, together, form a complete face! A typical CNN that is trained to do facial recognition, should also learn to identify these features. Only, by distilling an image into a feature-level representation, you might get a weird result:
- Given an image of a face that has been photoshopped to include three eyes or a nose placed above the eyes, a feature-level representation will identify these features and still recognize a face! Even though that face is fake/contains too many features in an atypical orientation.
So, there has been research into classification methods that do not discard spatial information (as in the pooling layers), and instead learn to spatial relationships between parts (like between eyes, nose, and mouth).
One such method, for learning spatial relationships between parts, is the capsule network .
Capsule Networks
Capsule Networks provide a way to detect parts of objects in an image and represent spatial relationships between those parts. This means that capsule networks are able to recognize the same object, like a face, in a variety of different poses and with the typical number of features (eyes, nose , mouth) even if they have not seen that pose in training data.
Capsule networks are made of parent and child nodes that build up a complete picture of an object.
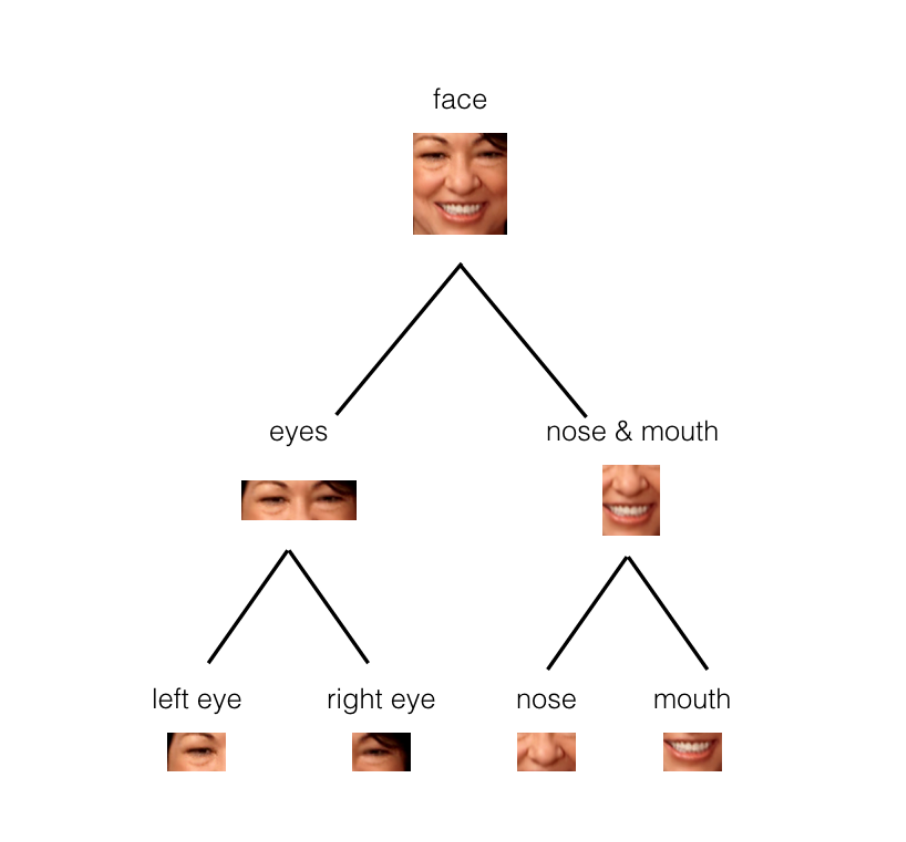
In the example above, you can see how the parts of a face (eyes, nose, mouth, etc.) might be recognized in leaf nodes and then combined to form a more complete face part in parent nodes.
What are Capsules?
Capsules are essentially a collection of nodes, each of which contains information about a specific part; part properties like width, orientation, color, and so on. The important thing to note is that each capsule outputs a vector with some magnitude and orientation.
- Magnitude (m) = the probability that a part exists; a value between 0 and 1.
- Orientation (theta) = the state of the part properties.
These output vectors allow us to do some powerful routing math to build up a parse tree that recognizes whole objects as comprised of several, smaller parts!
The magnitude is a special part property that should stay very high even when an object is in a different orientation, as shown below.
.](img/screen-shot-2018-11-27-at-2.48.28-pm.png)
Cat face, recognized in a multiple orientations, co: this blog post .
Resources
- You can learn more about capsules, in this blog post .
- And experiment with an implementation of a capsule network in PyTorch, at this github repo .